Check Proxy
will be working or not
export
http_proxy="http://xxxxx.xx.xx.net:3128/"
export
https_proxy="http://xxxxx.xx.xx.net:3128/"
export
no_proxy=localhost,127.0.0.1,Host IP (LINUX HOST IP)
export
DOCKER_HOST="tcp://127.0.0.1:2375"
After
setting the exports, then check
.
wget www.google.com
Getting 200 means proxy is working fine.
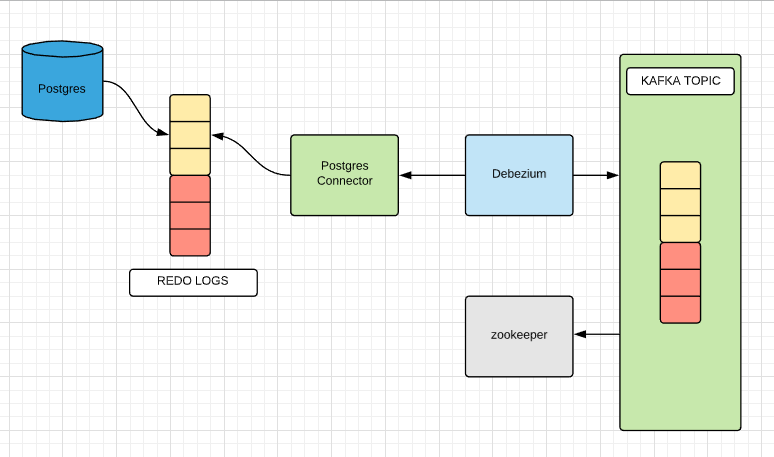
Debezium
Architecture
Using Change Data Capture (CDC) is a must in any
application these days.
No one wants to hear that the changes they made did not
reflect in the analytics because the nightly or hourly sync job has not pulled
or pushed the data. The common problem is that there are a raft amount of web
applications which are OLTP (Online Transaction Processing) and are often
backed by a relational database such as Oracle, PostgreSQL, MySQL etc.
Performing real-time data analytics on these database
systems requires usage of big joins and aggregations which results in locks as
these database systems are ACID complaint and provide good isolation levels.
These locks may be held for a long duration which could
affect the performance of the application for the live users.
Solution
- Change Data Capture Pattern:
-----------------------------------------------------
Thus, it makes sense to stream data into other teams of
your organisation which could perform analytics on it using spark jobs, hive
queries or whatever is your preferred framework for big data madness.
The following technologies will be used to accomplish
capturing data change.
Apache Kafka — It will be used
to create a messaging topic which will store the data changes happening in the
database.
https://kafka.apache.org/
https://kafka.apache.org/
Kafka Connect — It is a
tool used for scalable and reliable data streaming between Apache Kafka and
other systems. It is used to define connectors which
are capable of moving data from entire databases into and out of Kafka. The
list of available connectors is available here.
Debezium — It is a tool
used to utilise the best underlying mechanism provided by the database system
to convert the WALs into a data stream. The data from the database is then
streamed into Kafka using Kafka Connect API.
https://github.com/debezium/debezium
https://github.com/debezium/debezium

Capturing
data from PostgreSQL into Apache Kafka topics.
Debezium uses logical decoding feature available in
PostgreSQL to extract all persistent changes to the database in an easy to
understand format which can be interpreted without detailed knowledge of the
database’s internal state. More on logical decoding could be found here.
Once, the changed data is available to Debezium in an
easy to understand format it uses Kafka Connect API to register itself as one
of the connectors of a data source. Debezium performs checkpointing and only
reads committed data from the transaction log.
Let us run an example
To run this example you will require docker.
Start a PostgreSQL instance
docker run --name postgres -p 5000:5432 debezium/postgres
Start a Zookeeper instance
docker run -it --name zookeeper -p 2181:2181 -p
2888:2888 -p 3888:3888 debezium/zookeeper
Start a Kafka instance
docker run -it --name kafka -p 9092:9092 --link zookeeper:zookeeper debezium/kafka
Start a Debezium instance
One important point here:
Check in your docker instance echo $DOCKER_HOST, if it’s not there then
export DOCKER_HOST="tcp://127.0.0.1:2375"
checking cut command:
-----------------------------------------------------------
$(echo $DOCKER_HOST | cut -f3 -d'/' |
cut -f1 -d':')
echo "tcp://0.0.0.0:2375" |
cut -f3 -d'/' | cut -f1 -d':'
check cut command working or not.
docker run -it --name connect -p 8083:8083 -e GROUP_ID=1
-e CONFIG_STORAGE_TOPIC=my-connect-configs -e OFFSET_STORAGE_TOPIC=my-connect-offsets
-e ADVERTISED_HOST_NAME=$(echo $DOCKER_HOST | cut -f3 -d'/' | cut -f1 -d':')
--link zookeeper:zookeeper --link postgres:postgres --link kafka:kafka
debezium/connect
Connect to PostgreSQL and create a
database to monitor
docker exec -it postgres psql -U postgres
psql -h localhost -p 5000 -U postgres
CREATE DATABASE inventory;
CREATE TABLE dumb_table(id SERIAL PRIMARY KEY, name VARCHAR);
CREATE TABLE dumb_table(id SERIAL PRIMARY KEY, name VARCHAR);
What
we just did?
We started
PostgreSQL database and bound its port to 5000 for our system. We also started
zookeeper and which is used by Apache Kafka to store consumer offsets. At last,
we started a debezium instance in which we linked our existing containers i.e
postgres, kafka and zookeeper. The linking will help in communicating across
the containers.
Our setup is
ready we just now need to register a connector to Kafka Connect.
Create connector using Kafka Connect
url -X POST -H "Accept:application/json" -H
"Content-Type:application/json" localhost:8083/connectors/ -d '
{
"name":
"inventory-connector",
"config": {
"connector.class":
"io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname":
"postgres",
"database.port": "5432",
"database.user":
"postgres",
"database.password":
"postgres",
"database.dbname"
: "inventory",
"database.server.name":
"dbserver1","database.whitelist":
"inventory","database.history.kafka.bootstrap.servers":
"kafka:9092","database.history.kafka.topic":
"schema-changes.inventory"
}
}'
Response:
{"name":"inventory-connector",
"config":{"connector.class":"io.debezium.connector.postgresql.PostgresConnector",
"tasks.max":"1","database.hostname":"postgres","database.port":"5432","database.user":"postgres","database.password":"postgres","database.dbname":"inventory","database.server.name":"dbserver1","database.whitelist":"inventory","database.history.kafka.bootstrap.servers":"kafka:9092","database.history.kafka.topic":"schema-changes.inventory","name":"inventory-connector"},"tasks":[],"type":"source"}
Verify the Connector is created
curl -X GET -H "Accept:application/json"
localhost:8083/connectors/inventory-connector
{"name":"inventory-connector",
"config":{"connector.class":"io.debezium.connector.postgresql.PostgresConnector",
"database.user":"postgres",
"database.dbname":"inventory",
"tasks.max":"1",
"database.hostname":"postgres","database.password":"postgres",
"database.history.kafka.bootstrap.servers":"kafka:9092",
"database.history.kafka.topic":"schema-changes.inventory",
"name":"inventory-connector","database.server.name":"dbserver1",
"database.whitelist":"inventory","database.port":"5432"},"tasks":[{"connector":"inventory-connector","task":0}],"type":"source"}
Start a Kafka Console consumer to watch
changes
docker run -it --name watcher --rm --link
zookeeper:zookeeper --link kafka:kafka debezium/kafka watch-topic -a -k
dbserver1.public.dumb_table
Result
Now issue some
SQL inserts, updates and deletes from PSQL CLI. You will see some JSON like
output in the console consumer of watcher.
Reference:
https://medium.com/@tilakpatidar/streaming-data-from-postgresql-to-kafka-using-debezium-a14a2644906d